绪论
1. 引言
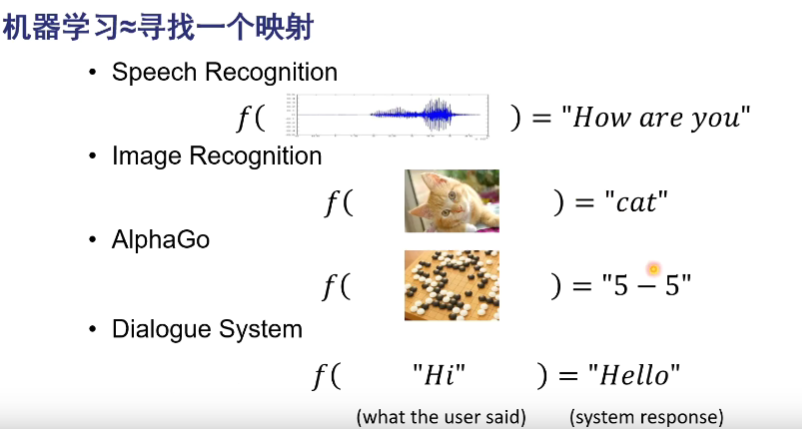
机器学习是什么?


接地气的说,人通过学习知识,能够对事情具有判断能力。
而机器也可以学习知识,从而对事情具有判断能力。
机器的知识是人提供的数据。
通过对数据的学习,从而训练出某种能力。
我们把给出这种能力的玩意叫模型。

2. 基本术语
假设我们现在要让机器一个任务,让它判断这个西瓜是否是个好瓜。
则我们需要给它数据进行学习,这个过程叫训练。
既然要判断好瓜,则我们应该给它西瓜的数据,并标注好哪个是好瓜,哪个是坏瓜。
试想一下,让一个不懂事的小朋友去挑,你是不是也得告诉他好瓜具有什么特征?机器也是这样。
训练数据集
- 100个西瓜
特征
- 颜色(绿,红,青绿…)
- 根蒂(长,短….)
- 敲声(大,小…)
- …..
标签
- 好瓜还是坏瓜
有了一些西瓜,以及特征,与标签,我们现在就可以让机器去学习如何判断好瓜或者是坏瓜了。
基本任务
分类(标签是离散型)
好瓜与坏瓜 → 二分类问题
小瓜中瓜大瓜 → 多分类问题
回归(标签是连续型)
能长多重
任务类别
有监督学习
例如分类好瓜还是坏瓜,给了一些特征,计算机还是不能明白谁是好的,谁是坏的。因为它根本就没见过西瓜….所以,给了特征后,还要给它谁是好瓜,谁是坏瓜,这样特征与标签之间能够建立起联系,从而能够训练出模型来,去分类谁是好瓜谁是坏瓜。
分类和回归都是有监督学习。
无监督学习
核心思想:物以类聚,人以群分。这是先辈赐予我们的智慧,与先验知识。在计算机中,我们认为距离相近的为一类,而距离使用的是欧氏距离等来度量。
代表算法就是Kmeans。
无监督学习不需要标签,而是使用距离,自动归类。也是个分类任务。
进行预测
- 测试
- 测试样本
泛化能力

简单来说,有些学霸不怕考试,对于新遇到的题也总是能做对,这就是泛化能力强的表现。
增加训练集的样本数,可以增强泛化能力。
(题海战术,不就是这个意思吗….)
3. 假设空间
科学推理的手段
归纳:特殊到一般
狭义
从训练数据中得到概念
- 布尔概念:是或不是
假设就是各种情况
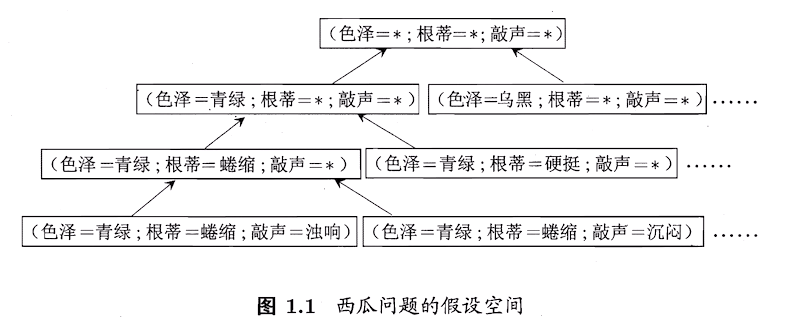
广义
- 从样本中学习
演绎:一般到特殊
4. 归纳偏好
同一个数据集训练出了不同的模型,如何选择模型?

原则
奥卡姆剃刀
选最简单的那个

也有其他的理解
因为简单的标准可能不唯一。
NFL定理
No Free Lunch Theorem.没有免费的午餐。

5. 发展历程
太多了

耐心的读者自己去读 我反正是没耐心
反正就是一种程序,有自我改善的能力,人为干预越少越好
6. 总结
这一章就是划划水,介绍基本内容啦。

