声明:爬取数据仅供学习用途
最近看了两部电影,就是最近讨论度很高的两部,《你好,李焕英》和《唐人街探案3》。个人拙见,《你好,李焕英》虽好,但过誉;《唐探3》虽差,但没那么不堪。群众的眼睛是雪亮的,所以,接下来的工作是分析用户的评论。
1.数据准备
数据来自某瓣,自己爬取。
使用selenium库进行爬虫。
import pandas as pd
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
from selenium.webdriver.chrome.options import Options
from fake_useragent import UserAgent
import random
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
if __name__ == '__main__':
count = 0
df = pd.DataFrame()
for j in range(10):
proxy_list = get_proxy() #动态ip
PROXY = '--proxy-server={0}'.format(random.choice(proxy_list))
print(PROXY)
chrome_options = webdriver.ChromeOptions()
# 增加无头
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 防止被网站识别
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
desired_capabilities = chrome_options.to_capabilities()
desired_capabilities['proxy'] = {
"httpProxy": PROXY,
"noProxy": None,
"proxyType": "MANUAL",
"class": "org.openqa.selenium.Proxy",
"autodetect": False
}
driver = webdriver.Chrome(desired_capabilities=desired_capabilities)
print("https://movie.douban.com/subject/27619748/comments?start={}&limit=20&status=P&sort=new_score".format(
(j + 1) * 20))
driver.get("https://movie.douban.com/subject/27619748/comments?start={}&limit=20&status=P&sort=new_score".format((j+1)*20))
for i in range(20):
comm = driver.find_elements_by_xpath(
"//*[@id=\"comments\"]/div[{}]/div[2]/p/span".format(i+1))
date = driver.find_elements_by_xpath(
"//*[@id=\"comments\"]/div[{}]/div[2]/h3/span[2]/span[3]".format(i+1))
useful = driver.find_elements_by_xpath(
"//*[@id=\"comments\"]/div[{}]/div[2]/h3/span[1]/span".format(i+1))
df.loc[count,"comment"] = comm[0].text if len(comm)>0 else "null"
df.loc[count, "date"] = date[0].text if len(date)>0 else "null"
df.loc[count, "useful"] = useful[0].text if len(useful)>0 else "null"
count += 1
print(df)
df.to_csv("tangtan3.csv",encoding='UTF-8')
driver.close()
为了防止被封ip,可以去获取代理ip,并且一次获取多个,随机用。这样基本不会被反爬机制发现。
其中我们使用的xpath语法也非常友好,在chrome浏览器中有个插件:
根据开发者工具,先定位好元素在哪,可以直接copy出xpath代码。把xpath代码放到插件中检查一下是否是你想要的元素,如果是的话,就可以写到代码中了。
一共爬了三个属性,评论、日期、点赞数,星级评价暂时爬不下来…因为定位不着,挺迷的。还有日期和点赞数数据有点问题。
2.分析
每部电影只爬取了200条评论,因为超过200条评论需要登录才能继续查看。不想再捣鼓cookies,就先做200条的分析。
我们使用snownlp库对评论进行消极/积极情绪分析。即把评论映射到0-1的实数域上,它代表的意义是:积极情绪的概率,1代表积极情绪概率极高,0代表积极情绪概率极低,可以理解为消极概率极高。
p.s. 英文文本可以使用textblob库分析。
2.0 代码实现
底下是实现的代码。
import pandas as pd
from textblob import TextBlob
from snownlp import SnowNLP
import matplotlib.pyplot as plt
import numpy as np
import matplotlib
import wordcloud
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
df = pd.read_csv("lihuanying.csv",index_col=0)
data = []
words = []
for i in range(len(df)) :
comment = df.loc[i,"comment"]
s = SnowNLP(comment)
p = s.sentiments
df.loc[i,"sentiment"] = p
data.append(p)
print(s.words)
w = list(set(s.words))
print(w)
for i in w[:]:
if len(i.encode('utf8'))<=3:
w.remove(i)
words.extend(w)
print(w)
print(words)
w=wordcloud.WordCloud(width=1000,font_path="C:\\Windows\\Fonts\\STXIHEI.TTF",height=700)
w.generate(" ".join(words))
w.to_file("lihuanying.png")
print(df)
plt.hist(data, bins=10, normed=0, facecolor="blue", edgecolor="black", alpha=0.7)
# 显示横轴标签
plt.xlabel("积极情绪概率")
# 显示纵轴标签
plt.ylabel("频数")
# 显示图标题
plt.title("积极情绪概率分布直方图")
plt.show()
2.1 《你好,李焕英》分析
首先自然就是直方图啦~
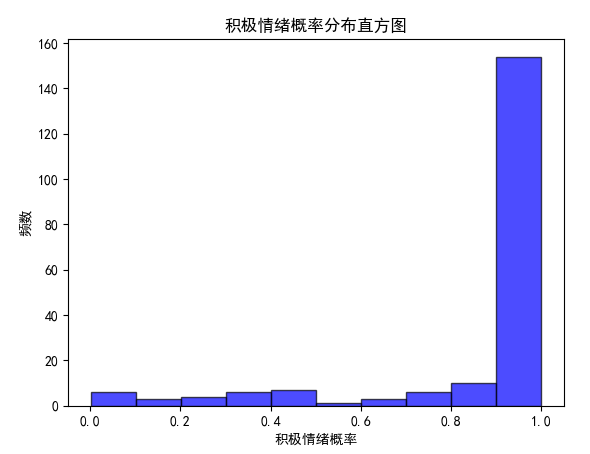
可以看到,1.0占比非常高。。说明观众对这个片子的评价还是很不错的。待会可以看一下唐探的评分,惨不忍睹呀。
接下来看看李焕英这个电影评论的关键词分布:

负面词很少,基本都是赞美= =
2.2 《唐探3》分析
emmm,我都不敢放图了,这还只爬了200条,情况就已经成这样子了。
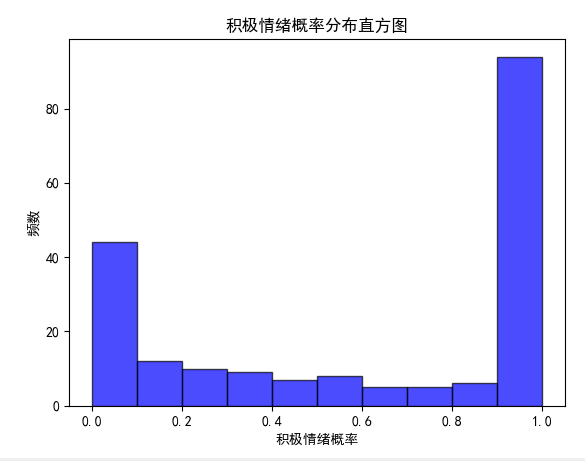
吊打局。而且消极评论占比还挺大,超过五分之一了。
接下来看看评论的关键词分布:

除去那几个最大字号的,你可以看到。。一些比较消极的词= =
3. 总结
大概就是做个小project试试水啦,不过还是蛮好玩的。如果大家有什么好点子,欢迎私信我(doge)。

